

Introduction: the coding problem no one talks about out loud
A billing manager at a mid-size clinic notices a pattern that doesn’t trigger a panic, but it does trigger a drain. The claims aren’t being denied for obvious errors; they are simply coming back lighter than the complexity of the care provided. The visits were thorough and the care was real, yet the codes never fully captured the story.
For a primary care group, the leak might be under documented chronic condition management. For a behavioral health clinic, it might be missed psychotherapy add-on codes. For a community health center, it might be telehealth claims denied because modifiers vary across payers. Different settings, same problem. The system expects humans to hold too many moving parts in their heads at once.
This is the routine reality of modern healthcare. With over 70,000 ICD-10-CM codes and a constant stream of payer-specific updates, medical coding has become a human endurance sport that the current system makes nearly impossible to win. At blueBriX, we believe the solution isn’t to ask your team to work harder, but to provide them with a system designed for their success.
In this article, you will discover why undercoding is often more financially damaging than a denied claim, get a concrete look at how AI can transform workflows from reactive “rework” to proactive “clean claims”, how to use AI as a defensive shield against audit risk and “rule drift” and seven critical criteria to use when auditing your current RCM technology. Read on to learn how to move beyond manual complexity and start building a system that amplifies your team’s expertise.
Why medical coding has always been a human endurance sport
Medical coding has always demanded judgment, precision, and speed. What has changed is the complexity packed into the same amount of time. ICD-10-CM carries more than 70,000 diagnosis codes. CPT codes change every year. Payers update their rules on their own schedules. A coder in a modern ambulatory organization may touch primary care, virtual care, behavioral health, and specialty workflows in the same week each with different documentation expectations, payer edits, and denial patterns. It is not that billing teams are undertrained. It is that the environment changes faster than any team can absorb without systematic help.
The stakes are highest in value-based care. HCC undercoding is a misrepresentation of patient complexity. Uncaptured chronic conditions, underdocumented SDOH factors, missed add-on codes, and payer-specific modifier errors do not announce themselves. They drain revenue quietly, suppress risk scores, and make high-acuity panels look easier to manage than they are. Industry estimates place coding error rates between 25 and 40 percent, with most errors skewing toward underpayment. The system produces those mistakes not because people are careless, but because the workflow was never built for this level of complexity at this volume. That is what AI-assisted coding exists to fix.
What AI-assisted medical coding actually means (and what it doesn’t)
AI-assisted coding has become one of those phrases that everyone hears and very few people define clearly. For some, it sounds like a futuristic replacement for coders. For others, it sounds like risky automation with a compliance problem waiting to happen. Neither view is especially useful.
At its simplest, AI-assisted coding uses natural language processing to read clinical documentation and suggest likely codes, flag documentation gaps, and surface patterns that humans often miss under time pressure. It does not autonomously submit claims. It does not replace final coder review. It does not make judgment calls on its own. It is an assistive layer, not an independent actor.
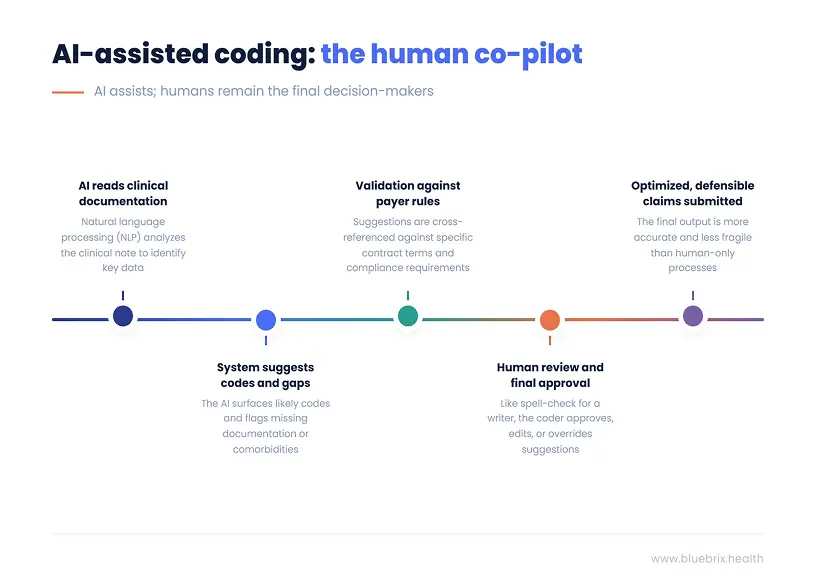
That distinction matters more than most people realize because the same principle applies whether you’re talking about a coding suggestion engine or a full AI orchestration platform. The architecture that makes AI useful in any clinical or revenue context follows the same logic: AI suggests; the platform validates. The human is still accountable for what leaves the system.
Good AI coding tools can surface missed codes, identify secondary diagnoses supported by the note, prompt for comorbidities or SDOH factors that affect acuity, and cross-reference payer-specific rules before the claim goes out. In a value-based care environment, that last capability is especially consequential. Every payer runs a different playbook, different HCC models, different modifier requirements, different thresholds for shared savings. An AI layer that checks a coding suggestion against your actual contract terms and payer rules before it touches the claim is doing something categorically different from one that just pattern-matches against a code set.
They can also spot trends across the organization. If a certain clinic consistently undercodes chronic care complexity, or a certain payer keeps denying telehealth claims because of a modifier mismatch, the system can flag the pattern before finance discovers it weeks later. That kind of closed-loop visibility from clinical note to validated code to submitted claim to denial pattern is what separates an AI coding assistant from a genuine orchestration layer.
What AI coding tools do not do is guarantee compliance or remove human accountability. They do not replace certified coders. They do not replace the need for internal auditing. They do not turn vague notes into precise claims. If the clinical documentation is incomplete or unclear, the AI cannot create specificity out of thin air. And no amount of orchestration infrastructure changes that. The context has to exist before any layer can govern it.
The best way to explain the model is the co-pilot analogy. AI-assisted coding works alongside the billing team the way spell-check works alongside a writer. It catches what is easy to miss at volume. It surfaces alternatives. It flags inconsistencies. But the human is still the author. The human still decides what leaves the page.
That is also why the automation anxiety argument is usually misframed. The question is not whether AI will eliminate coding jobs. The real issue is that many organizations already cannot hire enough strong coders, and the work keeps getting more complex especially as value-based contracts layer quality metrics, HCC risk scores, and payer-specific rules on top of an already demanding baseline. In that environment, augmentation is not a luxury. It is the only viable path to keeping up without burning out the people already carrying the load.
The practical workflow is simple enough to explain in one line. Clinical note enters the system. The NLP engine reads it. Suggested codes surface for review. Every suggestion gets validated against payer rules, contract terms, and compliance requirements. The coder approves, edits, or overrides. The claim goes out cleaner and more defensible than it would have without the assistive layer.
That does not make coding automatic. It makes it less fragile. And in a reimbursement environment where the margin for documentation error keeps shrinking, less fragile is exactly what the work needs to be.
The revenue you’re probably leaving on the table right now
Most revenue conversations in healthcare focus on denials, underpayments, or reimbursement cuts. They should. But one of the biggest leaks in the system does not show up as an obvious denial at all. It shows up as undercoding.
Undercoding is financially damaging in a way that is almost too quiet to detect. It rarely triggers an audit. It rarely gets the dramatic label of “compliance risk.” Instead, it just drains the organization slowly. A claim goes out at a lower level than supported. A secondary diagnosis never makes it onto the bill. A time-based or complexity-based add-on is clinically justified but administratively skipped. No one sounds the alarm because the claim still gets paid. It is just paid less than it should have been.
Three patterns show up again and again across settings.
Failure to capture the full complexity of comorbid diagnoses
A diabetic patient may also have depression, obesity, neuropathy, or renal disease that materially affects treatment and risk. If only the primary diagnosis gets coded, the payer sees a flatter, simpler patient than the one the team is actually managing. The patient looks healthier than they are on paper. In fee-for-service, that may mean lower payment. In value-based contracts, it means weaker HCC risk adjustment, a lower RAF score, and less favorable benchmarking. The organization ends up doing high-touch work for high-need populations while the financial model assumes it is caring for a lower-acuity panel. That gap does not correct itself. It compounds.
Chronic failure to document and code social risk
SDOH factors are often present in the note, especially in community health and behavioral health settings, but they never reach the coded record. That means the organization loses visibility into barriers that affect acuity, adherence, and outcomes. It also means analytics and value-based care models are working from a cleaner story than the care teams are living. You referred a patient to a food pantry. Did they go? Did it change their adherence picture? If SDOH never closes the loop from note to code to record, that entire layer of patient complexity stays invisible to the systems that price and benchmark the work.
Missing add-on, time-based, or complexity-level codes
This happens mostly because the workflow does not support reliable capture under volume pressure. It is common in primary care, behavioral health, and hybrid care models where clinicians are doing layered work that the claim never fully reflects. Chronic care management opportunities go uncaptured because no one can verify eligibility at scale. Psychotherapy add-on codes get missed in E/M visits with embedded therapy. Telehealth claims fail because one payer’s modifier logic gets applied to another payer’s contract. Every insurer runs a different rulebook, and without a system that validates coding suggestions against payer-specific requirements before the claim goes out, those mismatches become a rework backlog instead of caught errors.
This is where the value-based care compounding effect becomes serious. In a VBC environment, undercoded patients drag down more than claim revenue. They weaken RAF accuracy, reduce shared savings potential, and make panels look easier to manage than they really are. The financial model stops reflecting clinical reality and leadership ends up making decisions against a picture that was already wrong before month-end close.
Then there is the rework cost. Industry benchmarks often place average first-pass denial rates in the 10 to 15 percent range, and organizations with highly manual coding workflows can exceed that, particularly in telehealth-heavy and multi-payer environments. Reworking a denied claim is expensive, often landing somewhere between $25 and well over $100 per claim once staff time, correction cycles, and delayed cash are factored in. Every preventable denial becomes a mini-project. And every mini-project is time a billing team is spending on claims that should have gone out clean the first time.
When coding problems are caught only after submission, the financial picture is already distorted. A leadership team reviews month-end performance, not realizing a chunk of the claims still needs rework. Weeks later, the corrections come in, and the organization discovers that the revenue picture it was managing against was wrong. That is not just frustrating. It undermines decision-making at exactly the moment that CFOs and operational leaders need clear numbers to protect shared-savings performance.
The specialty examples make this tangible.
- A primary care group loses revenue on chronic care management because the organization cannot systematically identify which patients meet eligibility criteria and which minutes were properly captured. An AI layer embedded in the workflow surfaces the likely CCM opportunities and the missing documentation evidence before billing becomes guesswork and before month-end reveals the gap.
- A behavioral health clinic misses psychotherapy add-on codes attached to E/M visits because no one can see the pattern across all providers at once. The problem lives in aggregate, not in any single chart. An orchestration platform that tracks coding patterns across the population (not just one encounter at a time) spots the gap and flags it before it becomes a permanent revenue leak.
- A community health center keeps seeing telehealth denials because modifier requirements differ across payer contracts. Blue Cross requires a specific modifier that Aetna does not. Medicaid has a different rule again. Without a system that validates coding against payer-specific rules before submission, the mismatch does not get caught until the remittance cycle at which point the cost is already baked in.
That is the core of this whole article. The revenue is already in the room. The clinical documentation supporting it already exists. The problem is that most organizations have no reliable mechanism to connect what is in the note to what ends up on the claim and then validate that claim against the payer rules that will determine whether it actually gets paid. That connection is where AI-assisted coding, done properly, earns its place in the workflow. Not by automating accountability out of the picture, but by making it structurally harder to leave justified revenue behind.
How AI changes the coding workflow - a before/after look
The fastest way to understand the operational difference is to compare what the coding workflow looks like before and after AI assistance is embedded in it.
Before AI-assisted coding
The coder reads the note after the encounter and codes from memory, training, and experience. There is no automated cross-check against payer-specific rules at scale. Denials are often discovered at the clearinghouse stage or later, on remittance — at which point the cost is already baked in. Secondary diagnoses and SDOH codes are skipped under time pressure because the workflow gives no prompt to surface them. HCC gaps are identified, if they are identified at all, during annual chart review or retrospective audit — meaning an entire year of risk adjustment opportunity has already passed. Coding quality varies significantly depending on who touched the chart, how overloaded they were that day, and how current they are on the specific payer rule set involved.
For the Revenue/Finance Owner, this translates directly into the month-end close problem: a P&L stitched together from EHR data, clearinghouse claims status, and bank deposits — often running 10 to 15 days behind — while a portion of the claims in that picture still need rework that has not been accounted for yet. Decisions get made against a revenue picture that was already wrong.
For the operational leader, it looks like teams spending hours logging into payer portals, manually checking eligibility, chasing prior authorizations, and building color-coded Excel sheets to track who needs follow-up. High-risk patients do not always get prioritized because everyone looks the same inside the system. Different staff interpret “high risk” differently, so outreach is duplicated on some patients and missed entirely on others.
After AI-assisted coding
The NLP layer reads the note in real time — or during claim scrubbing — and surfaces likely codes for review before anyone has to rely on memory under pressure. A payer rules engine checks modifier logic and contract-specific requirements before the claim goes out, not after the remittance cycle reveals the mismatch. Documentation gaps are identified at the point of note completion, not after denial. Comorbidities and SDOH factors are prompted based on clinical language already present in the note — the AI is not inventing context, it is surfacing what is already there. HCC opportunities surface continuously across the population, not just at year-end when everyone is scrambling to recover what was missed in January.
Critically, every suggestion passes through a governance layer before it touches a contract, a payer, or a patient record. AI suggests. The platform validates against your actual VBC contract terms, payer-specific rules, HEDIS and STARS specifications, and CMS compliance requirements. Only validated actions move forward — with a full audit trail attached. That is not a small distinction. It is what separates a helpful suggestion from a defensible claim.
Baseline coding quality also becomes more consistent across coders because everyone is working with the same assistive framework and the same rules engine, not six different interpretations of the same payer’s requirements.

The nuance that determines whether any of this actually works
AI coding is only as good as the documentation that feeds it. If the note is vague, the AI will only be vaguely useful. If the clinical narrative leaves out the condition entirely, the AI cannot ethically or safely invent it. That is why AI-assisted coding and documentation improvement are inseparable. The better the upstream note, the stronger the downstream coding support and the stronger the downstream revenue and risk adjustment picture.
This is also why the EHR platform matters more than most people acknowledge when evaluating AI coding tools. If the AI layer sits outside the clinical workflow, bolted on as a separate tool the billing team consults after the note is complete, it becomes just another disconnected system that requires a separate login, a separate workflow step, and a separate reason for staff to engage with it. Which, under volume pressure, they will skip.
If it sits inside the workflow, where documentation is actually created, then the assistive prompts arrive when they are still useful. The coder reviewing a note gets the comorbidity prompt before the claim is coded, not after it is submitted. The care team completing documentation gets the SDOH flag before the encounter closes, not during a retrospective audit six months later. The billing team sees the payer rule conflict before the claim leaves the system, not when the denial comes back.
That is the architectural argument for a platform like blueBriX where EHR, RCM, care coordination, and the AI orchestration layer are not integrated after the fact but built to operate together from the same unified record. A coding agent is only valuable if it can submit the claim. A risk stratification agent is only valuable if it can trigger an outreach. The intelligence and the execution have to live in the same system for the loop to actually close.
The operational shift, then, is not abstract. It is the difference between discovering problems after they have already hit cash and having a governed, validated layer that prevents them from leaving the system in the first place.
The compliance risks AI can help you avoid
Compliance-minded teams do not need a sales pitch. They need a sober answer to one question: does AI make coding safer or riskier?
The honest answer is that it can do either, depending on how it is implemented. Poorly governed AI like an agent operating without a validation layer, without contract context, without a full audit trail, creates new ambiguity. Well-governed AI reduces the common and expensive errors that already expose organizations to payer audits and OIG scrutiny. The difference is not which AI model you are using. It is whether the AI is operating inside a governance framework that knows the difference between what the model suggests and what the contract and compliance requirements will actually support.
- Overcoding and upcoding drift – A well-governed AI coding system flags when a suggested code does not align cleanly with the documented clinical evidence. Every suggestion gets validated against the clinical record and contract logic before it touches a claim. That validation layer is what separates a defensible coding decision from one that looks fine until an auditor asks for the original note.
- Telehealth compliance – An AI-powered rules engine standardizes those checks at the payer level, so the same type of visit is not coded three different ways by three different staff members and so Blue Cross’s modifier requirements are not accidentally applied to an Aetna claim because someone was working from memory.
- Payer-specific rule drift – A rules engine that updates in sync with payer logic and validates against your actual VBC contract terms removes the burden of chasing those changes on your own. The contract is the authority. The system enforces it, every time.
- Audit trail – A governed AI-assisted coding platform can document what the system suggested, what the coder accepted or overrode, and the reasoning attached to that decision. Only validated actions reach the claim, with a full audit trail for every payer, program, and contract. Same governance standard, regardless of whether the agent involved is native to the platform or a third-party tool plugged into the orchestration layer.

System readiness audit: what to look for in a platform with ai-assisted coding
At some point, the conversation moves from should we do this to how do we evaluate this without getting trapped by the wrong platform. This is where organizations need practical criteria, not hype.
1.Specialty-aware coding logic
A platform that only understands generic coding patterns will struggle in the real world. Primary care, behavioral health, community health, and virtual care all have different code sets, different documentation standards, and different failure points. Behavioral health, in particular, has ICD-10 and DSM alignment requirements, CPT-specific add-on structures, and program-level billing rules for services like CCM and CCBHC that generic coding tools simply do not know how to handle. The AI needs to understand what it is reading, not just pattern-match against a code list.
2.Configurable payer rules engine
Medicare, Medicaid managed care, Medicare Advantage, commercial contracts, and CCBHC-specific billing all carry different requirements for modifiers, place-of-service codes, documentation thresholds, and claim structure. If the rules engine cannot reflect payer-specific logic at the contract level, the platform will surface helpful coding suggestions and still leave denial prevention on the table. The test is simple: ask the vendor how their system handles a situation where Blue Cross and Aetna have conflicting modifier requirements for the same service type. The answer tells you everything about the depth of the rules layer.
3.Native EHR integration
If the AI requires manual exports, batch uploads, or re-entry into a separate system, it creates friction at exactly the moment organizations are trying to remove it. A platform where the AI layer sits outside the clinical workflow, bolted on rather than built in, will be used inconsistently, especially under volume pressure. The strongest tools read notes from within the workflow and return guidance where clinicians and coders already are, without requiring a separate login or a parallel process.
4.Human override and audit trail
Coders must be able to override suggestions. Every override, every acceptance, and every exception must be logged with a timestamp, a user ID, and the reasoning attached. That history is what makes the system defensible in an audit. It demonstrates deliberate human review and organizational oversight, not opaque automation that no one can explain to a payer. If a vendor presents the audit trail as a premium add-on rather than a core function, that is a signal about how they think about governance.
5.Denial pattern analytics
A platform should not only improve individual claims. It should surface trend data so leadership can identify recurring payer issues, provider-specific coding gaps, and patterns of undercapture that compound over time. The CFO who cannot see which programs are profitable and which are losing money until the month-end close — working from stitched-together data across the EHR, the clearinghouse, and the bank — is operating without the visibility needed to protect VBC contract performance. The platform should close that gap, not just improve the claim at the encounter level.
Implementation and training support are strategic
An AI coding tool layered onto a stressed billing team without structured onboarding and workflow support will fail quickly because the people closest to the work were not brought along. Ask specifically how the vendor handles the transition period, what the onboarding model looks like for billing staff, and what happens when payer rules change after go-live.
6.HIPAA compliance must be explicit
The platform must process clinical note data in a fully compliant environment with a signed Business Associate Agreement, role-based access controls, and auditable access logs. For behavioral health organizations, 42 CFR Part 2 protections for substance use disorder records add a layer of specificity that must be addressed directly, not treated as a standard HIPAA extension. If a vendor cannot answer these questions clearly and immediately, the conversation should stop there.
Revenue Health Assessment
This is not a product evaluation checklist. It is a reality check. A platform that fails on these criteria will not solve the coding problem. It will digitize the chaos already in the system, add a layer of technical complexity, and leave the organization with the same revenue exposure plus a vendor contract.
The self-audit below is designed to help you assess where your organization stands before that conversation begins.


