

You already know how today’s healthcare environment works. The more systems you integrate, the harder it becomes to keep your data clean, aligned, and usable. Every EHR, lab feed, imaging system, pharmacy interface, and device stream adds value. It also adds another layer of uncertainty.
And the consequences show up fast. Delayed treatment decisions, mismatched patient info, frustrated clinicians, and workflows that slow down when you need them to move faster. These issues aren’t new. They’re the daily reality of trying to maintain accurate patient data across a multi-source ecosystem.
Manual verification has tried to keep this under control, but it simply can’t keep pace with the volume and velocity of data you deal with now. Teams spend hours reconciling inputs, yet the risk of missed discrepancies stays the same.
This is exactly why automated data verification has become foundational. When verification happens at every integration point, you move from managing data problems to preventing them. The result is a consistent, reliable single source of truth that supports faster decisions, stronger coordination, and safer patient care.
And while everyone in healthcare has accepted that fragmented data comes with the territory, most teams still rely on manual verification to keep things under control. The problem is that manual review was never designed for the volume, speed, or complexity of the data we work with today. Which brings us to the core issue.
The flaw in the manual system: limitations of human verification
Manual verification helps, but it can’t keep up with multi-source EHR integration. You’ve seen these limitations firsthand:
- It slows down clinical and administrative workflows because every check adds another bottleneck.
- Staffing costs rise quickly, and scaling reviewers is not sustainable as data volume grows.
- Fatigue and cognitive overload make it easy to miss subtle but critical discrepancies.
- Verification outcomes vary based on who reviews the data and how experienced they are.
- Large, complex, or high-velocity data sets are nearly impossible to validate consistently by hand.
- Audit trails and documentation often fall short, making compliance and traceability harder.
- Manual processes can’t support real-time or near-real-time decision-making in fast-moving environments.
- Different systems use different definitions and standards, creating more inconsistencies during review.
- Privacy and legal constraints complicate how data can be handled, increasing compliance risks.
Manual verification still has a place, but it was never designed for the scale and complexity of today’s data ecosystem. Moreover, healthcare is time sensitive. The gaps it leaves aren’t just inconvenient. They directly affect care coordination, safety, and operational speed. Which is why automated verification isn’t just a technical upgrade. It’s the only practical way to ensure data stays accurate as it moves across systems.
To make that possible, automated verification operates through three distinct layers that work together to catch the errors manual review simply can’t.
The core of automation: three layers of data verification
Once you move past the limits of manual review, the question becomes simple: how do you keep data accurate at scale? Automated verification solves this by validating every incoming record through three layers. Each layer catches a different category of errors, and together they create the reliability that multi-source ecosystems need.
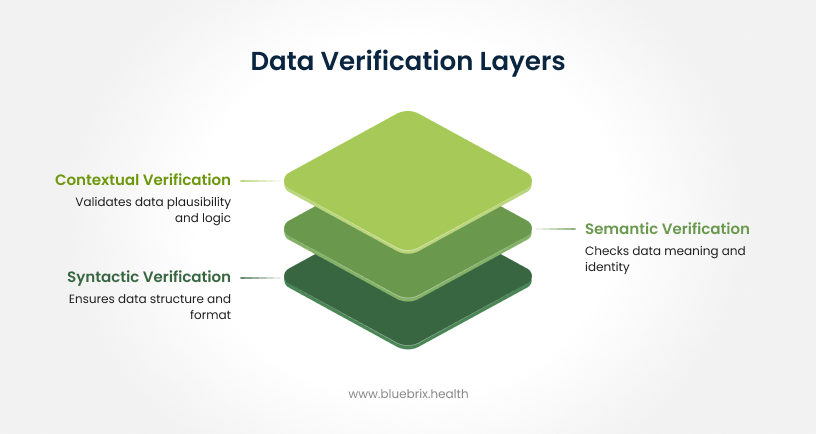
1. Syntactic verification (format and structure)
This layer makes sure the data arrives in the right structure.
- Checks whether messages follow standards like HL7 and FHIR
- Confirms fields have the correct type, length, and required information
- Normalizes formats so every system speaks the same language
Think of this as verifying the packaging of the data before looking at the content.
2. Semantic verification (meaning and identity)
Here, the system checks what the data actually represents.
- MPI matching algorithms detect and merge duplicate patient records
- Clinical codes are mapped correctly across standards like SNOMED CT, LOINC, RxNorm, and ICD-10
- Linked data is validated to ensure referenced records actually exist
This ensures the data not only looks right but also points to the correct patient, code set, and clinical meaning.
3. Contextual verification (plausibility and business logic)
Finally, the system checks whether the information makes sense in real-world care.
- Flags lab values that fall outside clinically acceptable ranges
- Validates the sequence of events, such as ensuring discharge isn’t logged before admission
- Identifies contradictions like a patient marked deceased but appearing on an active schedule
This layer protects against errors that are technically valid but clinically impossible.
With these three layers working together, automated verification does more than clean up data. It changes how information moves across your organization. Instead of constantly correcting issues after they appear, your systems prevent them before they reach clinicians or operational teams. And that shift creates very real, measurable improvements in day-to-day care coordination.
Why standard integration engines miss critical errors
Most integration engines stop at the basics. They validate whether an HL7 or FHIR message is formatted correctly, then push it downstream. In a multi-source EHR environment, that isn’t enough. The real risks hide in the gaps these commodity tools can’t see.
Here’s where the three layers actually matter, not as academic concepts but as the reason data still breaks even after “successful” integrations.
1. Where standard validators stop: syntactic checks only
Most tools validate structure but not substances. They’ll accept a perfectly formatted HL7 message even if it carries outdated allergies, mismatched demographics, or codes that no longer map across systems. The result: clean-looking data that still compromises care decisions.
2. The hidden failure point: semantic conflicts
When two systems disagree on who a patient is or how a clinical term is coded, typical engines don’t catch it. Duplicate MPI entries, mixed-up identifiers, misaligned code sets, and mismatched encounters slip through because nothing is checking meaning. These are the errors that derail downstream workflows and force teams into endless reconciliation.
3. The most dangerous gap: contextual errors
This is where liability lives. Standard engines don’t understand clinical logic or real-world plausibility. They can’t flag situations like:
- A “deceased” patient scheduled for surgery
- A discharge timestamped before admission
- Lab values that make no physiological sense
These aren’t formatting issues. They’re operational and clinical risks that surface only when multiple systems feed data into one environment.
Why blueBriX Is Different: blueBriX doesn’t just validate files. It validates reality. Its verification engine runs syntactic, semantic, and contextual checks together, closing the exact gaps where traditional tools fail. That’s what creates the reliability needed for real-time care coordination, faster decisions, and safer operations.
The direct benefits of automated data verification to care coordination
When your data is verified automatically at every integration point, the impact shows up quickly across clinical, operational, and administrative workflows. Here’s what organizations consistently gain:
More accurate patient information: Automated checks remove the small but critical errors that often slip through manual review, giving clinicians a reliable foundation for decision-making.
Faster access to updated data: Records sync more quickly because the system validates inputs in real time, reducing delays that affect care planning and treatment.
Stronger interoperability: Consistent formats, mapped codes, and clean data create smoother information exchange between all providers involved in a patient’s care.
Streamlined workflows: With fewer manual checks, teams spend less time on repetitive reconciliation and more time supporting clinical needs and complex cases.
Lower administrative burden: Eligibility, benefits verification, and claim-related tasks move faster and with fewer errors, reducing denials and improving reimbursement timelines.
Better patient experience: Shorter wait times, fewer billing surprises, and clearer communication all stem from having accurate, timely data at every touchpoint.
A foundation for proactive care: High-quality data powers predictive analytics and care pathway optimization, helping clinicians anticipate needs instead of simply reacting to them.
Together, these benefits ensure that everyone involved in a patient’s journey is working from one consistent source of truth, improving safety, outcomes, and operational efficiency.
A scenario from clearbrook behavioral health
To illustrate the impact of automated verification, imagine Clearbrook Behavioral Health, a multi-location practice juggling data from four different EHR systems. Every sync created new inconsistencies: duplicate patient profiles, demographic conflicts, and lab values that didn’t match across sources. Clinicians often waited for corrected records, and the admin team spent nearly 20 hours each week fixing data just to keep daily operations moving.
After Clearbrook enabled automated verification across its integration points, the first month delivered noticeable improvements:
- Upto 42 percent reduction in duplicate MPI records
- Nearly 68 percent fewer demographic mismatches
- Real-time updates instead of hours-long manual reviews
- 15 weekly admin hours saved
- Zero workflow delays caused by data discrepancies
In this example, automation transforms Clearbrook’s chaotic data environment into a stable, predictable system. Clinicians finally receive aligned information when they need it, and operational teams stop chasing issues and start focusing on patient care.
What to look for in an automated data verification solution
Once you decide to automate verification, the next step is choosing a solution that can actually keep your data trustworthy across every system feeding your EHR environment. The right platform doesn’t just clean data. It makes sure every record stays complete, consistent, clinically sound, and compliant as it moves across your organization.
The essential your solution must have
Real data quality intelligence: It should evaluate completeness, accuracy, consistency between sources, clinical plausibility, and freshness. In other words, it must catch the errors that matter most for patient care and operations.
Automated end-to-end workflow testing: Look for a system that can test real scenarios like registration, order entry, and results retrieval without anyone manually checking each step.
Strong standards support: FHIR, HL7, LOINC, SNOMED CT, RxNorm, and related frameworks should be native, not an afterthought. Interoperability starts here.
Clinical accuracy checks: Calculations, transformations, code mappings, and record completeness should all be validated so downstream clinicians work with information they can trust.
Compliance and audit readiness: HIPAA safeguards, encryption, role-based access, and detailed audit logs should be built in. If it can’t defend an audit, it can’t verify your data.
AI-powered anomaly detection: Modern solutions use AI or ML to flag outliers, identify patterns, and normalize scattered inputs faster than rule-based systems alone.
Scalability and monitoring: Real-time dashboards, error rate tracking, and performance insights are essential when multiple EHRs and high-volume data feeds are involved.
Real-time or scheduled reconciliation: The system should instantly identify mismatches between sources and correct them so your single-source-of-truth stays intact.
How to evaluate a solution quickly
- It should work with your CI/CD or DevOps pipeline for continuous validation.
- Updates to mapping rules, test scripts, or clinical logic should be easy, not a redevelopment project.
- Tools proven in healthcare environments (like FHIR validators) are a safer bet.
- Reporting should be clear, structured, and usable for audits, alerts, and compliance reviews.
This is the level of capability organizations need to protect data integrity and reduce errors across multi-source EHR environments. Anything less creates more work for your teams and more risk for your patients.


