

Digital healthcare records are indispensable to modern medicine. However, their efficacy hinges on robust security measures and dependable infrastructure; without these, they pose significant risks. Electronic Health Records (EHRs) now serve as the foundational backbone for streamlined patient care, making system uptime absolutely critical. Digital health downtime disrupts clinical workflows, delays crucial diagnostic and treatment decisions, and fundamentally compromises patient safety. Research indicates, for instance, an average 62% delay in laboratory testing results during system outages. When healthcare providers lose real-time access to accurate patient data, the quality of care suffers immediately.
blueBriX solutions leverage AWS cloud services and addresses this challenge head-on with unwavering reliability and data integrity. We utilize robust infrastructure and advanced failover mechanisms to minimize downtime risks, ensuring seamless access to vital health information when it matters most. Ultimately, blueBriX safeguards both patient care and operational efficiency through engineered resilience.
blueBriX strategy for disaster recovery - minimal downtime & maximum data restoration
Our comprehensive digital health data recovery strategy focuses on defining critical recovery benchmarks (RTO and RPO) and implementing three foundational pillars for uninterrupted patient care. This approach combines high availability through system redundancy, robust disaster recovery with multi-region backup centers, and automated backup with continuous monitoring to deliver seamless healthcare operations regardless of system failures or emergencies.
Core objectives for data recovery plan
- Recovery time objective (RTO): How quickly can we get our systems back up after a problem? The shorter the RTO, the faster your hospital or clinic can return to normal and start helping patients again.
- Recovery point objective (RPO): How much data can we afford to lose if disaster strikes? A lower RPO means you lose less patient information or records—ideally, everything is backed up and up to date.
Pillars of our approach for minimal downtime
Our healthcare IT infrastructure is built on three foundational pillars that ensure uninterrupted access to critical patient data and systems. We combine high availability through system redundancy and automated failover, comprehensive disaster recovery with multi-region backup centers, and real-time data protection with continuous monitoring to deliver 24/7 healthcare service reliability.
High availability: designing for resilience against failures
System redundancy: All critical healthcare applications and data are hosted on multiple servers, often spread across different data centers or availability zones. This ensures that if one server or location fails, operations can instantly switch to another without disruption.
Continuous access: Patient records and essential systems are always reachable, even during unexpected outages or heavy usage periods. This reduces downtime and keeps care delivery uninterrupted.
Automated failover: Our systems are capable of automatically shifting workloads to healthy resources when issues are detected, minimizing manual intervention and response times.
Disaster recovery: ensuring seamless restoration of data and functionality
Standby data centers in different region: Alongside our main data center, we set up another data center in a separate region. This backup center is fully configured and connected but doesn’t run your day-to-day operations. Instead, it quietly keeps up-to-date copies of your patient records and system settings in sync with the main center.
Automatic or easy failover: If a major disaster—like a nuclear incident hits the primary data center, your system can automatically switch over to the backup center in the other region. This means your staff can keep working and accessing vital information, often without even noticing the change.
Ready without waste: Because the backup center isn’t running constantly, you save on costs, but it’s always ready to take over at a moment’s notice. This setup keeps healthcare services available with minimal downtime or interruption, even during the most severe emergencies.
Automated backup, monitoring, and recovery
Backups – real-time data protection: We provide real-time or near real-time backups, so your patient records, test results, and other critical healthcare data are automatically saved and updated the moment changes happen, not just once a day. If there’s ever a problem or outage, we can quickly restore the latest information, minimizing any data loss and keeping your operations running smoothly.
Monitoring – application and server health: Continuous monitoring tools keep a close eye on your healthcare systems at all times. This includes tracking how much CPU, RAM, and storage each application and server is using. By watching these metrics, IT teams can spot potential issues early—like when a server is getting overloaded, or storage is running low—and fix them before they become major problems. This proactive approach helps maintain system performance, ensures uptime, and keeps patient care running smoothly.
Automated recovery: Restoration processes are streamlined and automated, allowing systems to return to service with minimal manual work. This includes auto-scaling resources to match demand during recovery periods.
By combining these pillars, our approach delivers continuous, reliable healthcare IT services—ensuring patients and staff always have access to the data and systems they need, regardless of the challenges faced.
Inside blueBriX's cloud infrastructure: key components for stability
For uninterrupted system performance and data security, blueBriX’s cloud infrastructure is built on five essential components that work seamlessly together. Our architecture features intelligent load balancers for efficient traffic distribution, secured application servers powering core operations, dedicated notification systems for smooth communication, high-speed caching to enhance user experience, and encrypted database servers to ensure comprehensive protection of patient data.
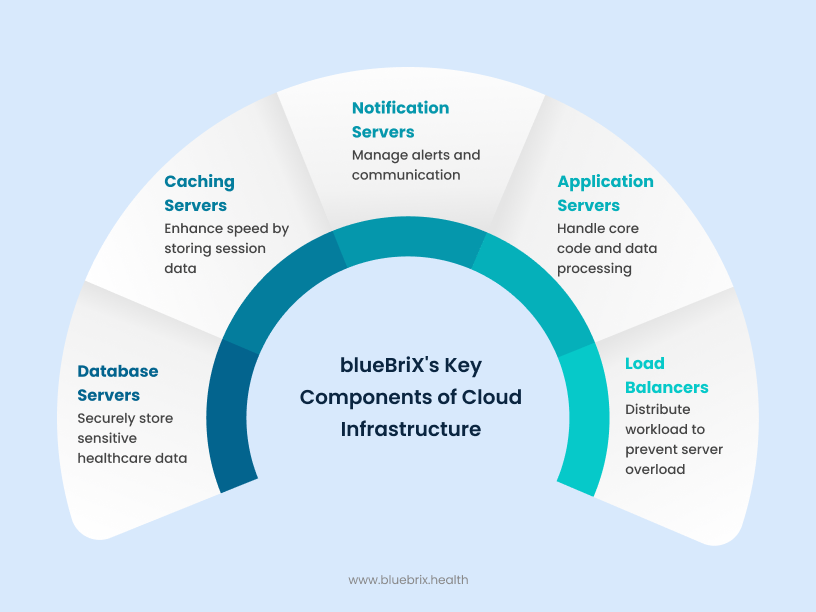
Load balancers: distributing the workload efficiently
Load balancers act like traffic managers that distribute incoming user requests evenly across multiple servers. This prevents any one server from getting overwhelmed, ensuring that your system stays fast and responsive even when the traffic is high. By balancing the workload, load balancers help avoid slowdowns and system crashes, keeping patient care smooth and uninterrupted.
Application servers: the heart of our system operations
This is where our core code runs, handling everything from patient data to appointment workflows. To keep things secure and stable, we never allow requests to directly hit our servers. Instead, all requests go through a request load balancer—an intermediary that smartly distributes traffic across multiple application servers. This prevents overload, ensures smooth performance, and minimizes any risk of downtime during peak usage.
Notification servers: keeping communication flowing
Notification servers manage alerts and messages within the system—such as appointment reminders, lab result updates, or emergency alerts. They ensure timely communication between healthcare staff and patients, helping coordinate care smoothly and prevent missed information.
Caching servers: enhancing speed and performance
Caching servers help manage individual user sessions—meaning when you log in, your details and activity are stored temporarily for fast access during your visit. This session data doesn’t need to be pulled from the main database every time you click, making your experience smoother and reducing wait times. By storing each user’s login session in memory, caching servers allow thousands of staff to use the system simultaneously without slowdowns, even at peak times, and make it easy to scale as your hospital grows. If the main data center goes down, user sessions can also be switched to a backup site instantly, so you can keep working with minimal disruption.
Database servers: securing your patient data
Database servers safely store all sensitive healthcare information—including medical histories, test results, and billing details in a secure and organized way. They handle high volumes of data with strong security measures to protect patient privacy and comply with healthcare regulations, ensuring that information is always available, accurate, and safe from unauthorized access.
Advanced strategies to minimize downtime in blueBriX
blueBriX employs multiple advanced AWS-powered strategies that work collectively to eliminate downtime and ensure continuous system availability. Our approach combines intelligent auto-scaling, multi-zone deployment, proactive health monitoring, and automated failover mechanisms across all system components—from application servers to databases and caching layers—delivering seamless healthcare operations even during peak usage or unexpected failures.
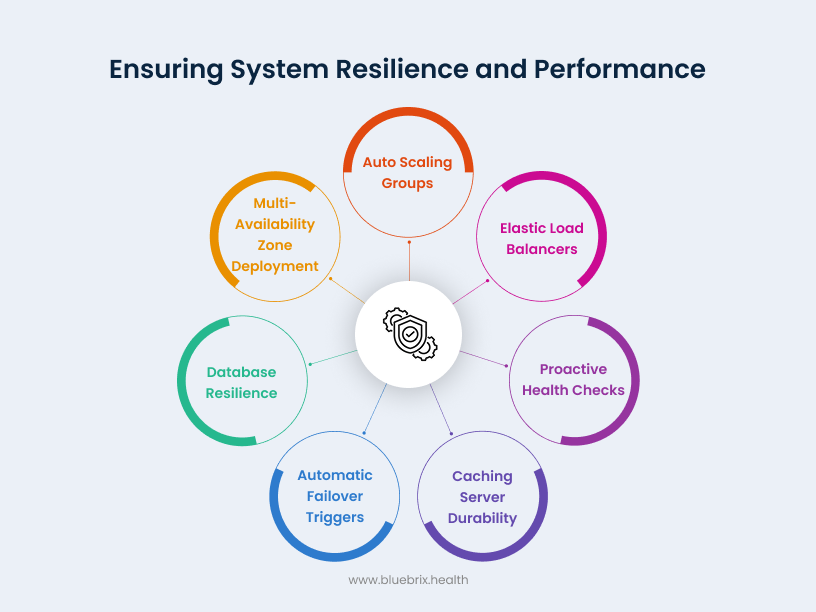
Auto scaling groups with AWS
With AWS auto scaling, the number of active servers adjusts automatically in response to real-time usage and system health. Therefore, during peak usage, it spins up additional servers to handle the load and maintain smooth system performance. When demand drops—like during off-hours—the system scales down, reducing the number of active servers to avoid unnecessary usage. We set both minimum and maximum limits for scaling, ensuring optimal system availability without overprovisioning. This dynamic approach guarantees performance and reliability.
Elastic load balancers
Elastic load balancers act like the middleman who routes requests to servers accordingly. They spread incoming user requests evenly across all active servers. If one server slows down or goes offline, the load balancer quickly shifts users over to others, maintaining speed and access for everyone using the system.
Multi-availability zone deployment
Multi-Availability Zone (AZ) deployment ensures high availability by spreading servers across multiple isolated data centers within a region. If one zone faces an issue—like a power outage or network disruption—other zones automatically step in to keep your system running without interruption. This setup is further strengthened by AWS Auto Scaling, which allows you to define where servers should be launched based on demand. You can scale resources up or down in specific zones, optimizing both performance and cost.
Proactive health checks
Automated health checks powered by Application Load Balancer (ALB) and CloudWatch constantly test each server and application’s availability and health status. If a problem is detected, it’s addressed instantly—either by alerting IT teams or by automatically rerouting traffic and spinning new instances—preventing downtime before users notice.
Database resilience
To ensure high availability and fault tolerance, our database setup on AWS follows a master-slave architecture—where one master server (writer node) handles all requests, and multiple slave servers (reader nodes) will have replicated data from the master. These nodes are typically deployed within the same or across multiple AWS Availability Zones for added resilience. In the event of a failure or downtime on the master node, AWS automatically promotes one of the reader nodes to become the new master, ensuring that the system continues to function seamlessly. When the original master recovers, it rejoins as a reader node. This built-in AWS failover mechanism allows uninterrupted access to critical patient data while maintaining consistency and system stability.
Caching server durability
Caching servers follow a structure similar to database resilience, using a primary-secondary architecture. The primary server handles all requests, while secondary servers store real-time replicas of this cached data. If the primary server fails, one of the secondaries is automatically promoted to primary, ensuring uninterrupted data access. When the original primary recovers, it rejoins the system as a secondary. This setup ensures high availability, fault tolerance, and consistent performance by keeping frequently accessed content readily available—even during outages.
Automatic failover triggers
When a critical system component fails, automatic failover springs into action—traffic and operations are instantly shifted to backup servers or regions with zero or minimal service interruption. This built-in resilience means clinicians and staff maintain access to EHR tools and patient records, regardless of outages or emergencies.
Safeguarding your data: blueBriX’s multi-layered security approach
blueBriX implements a comprehensive security framework that protects patient data through multiple defensive layers working in coordination. Our approach combines traffic regulation through rate limiters, advanced firewall protection against malicious requests, and geolocation-based access controls to create an impenetrable barrier that safeguards sensitive healthcare information from both automated attacks and unauthorized access attempts.
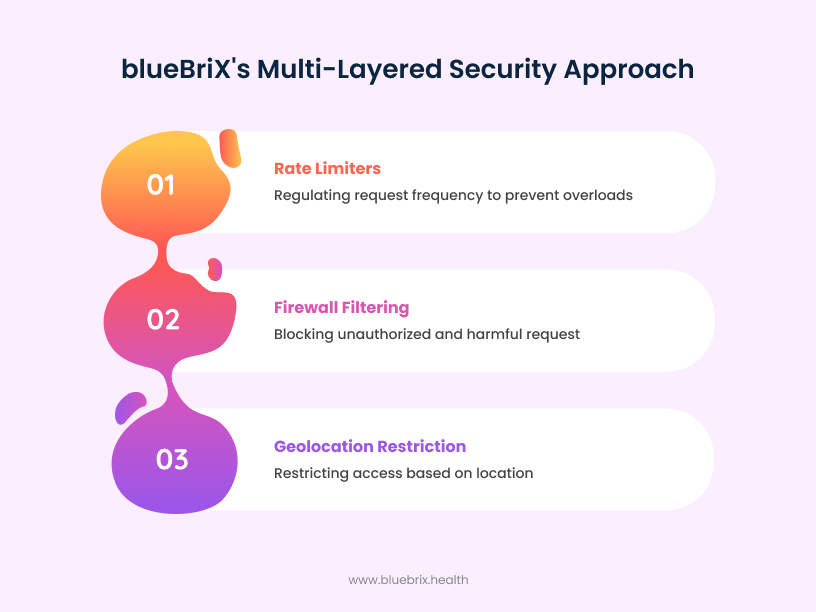
Rate limiters: protecting against traffic flooding
Rate limiters act as traffic regulators at the gate of our digital health solutions. They monitor how many requests are coming from a single user or IP address within a given time. If someone—whether unintentionally or with malicious intent—sends too many requests too quickly (a common tactic in DDoS attacks), the system automatically slows or blocks that traffic. This helps prevent system overloads, keeps genuine user access smooth, and acts as a front-line defense against suspicious activity.
Firewall configurations: blocking unauthorized and harmful requests
Robust firewall rules are set up to filter incoming and outgoing traffic based on predefined security policies. These firewalls sit in front of the load balancer and filter incoming requests before passing them on. They actively block unauthorized access attempts and harmful requests—such as SQL injections or known malicious IP addresses—before they ever reach our internal systems. Whether it’s at the network or application level, our firewalls form a critical barrier that shields sensitive patient data and keeps threats at bay.
Geolocation-based access restriction: enhancing security
To further reduce security risks, geolocation-based access controls are in place to allow system access only from approved countries or regions. If a login attempt comes from a location outside of allowed zones, it’s immediately denied or flagged for review. For example, if your hospital operates in US, there’s no reason traffic from other continents should be hitting your system. This makes it much harder for foreign or unauthorized actors to exploit the platform, adding an extra layer of region-specific protection.
Comprehensive data backup and restoration philosophy
blueBriX’s data protection strategy employs multiple backup methodologies and restoration techniques to ensure complete data security and recovery capabilities across all system components. From point-in-time restoration and automated/manual database snapshots to full AWS Backup coverage, we deliver flexible recovery, regulatory compliance, and zero-tolerance for data loss in healthcare operations.
Database server backups
Our data backup philosophy includes continuous protection of the primary database server to safeguard vital patient and operational data.
Point-in-time restoration
Point-in-Time Restoration (PITR), an AWS feature allows you to restore your database to any specific second within a defined window, depending on the configuration. This is especially useful in scenarios like accidental deletions, data corruption, or erroneous updates. By leveraging continuous transaction logging and incremental backups, PITR provides precise recovery options without requiring a full rollback, ensuring minimal data loss and faster resolution. It’s like having a rewind button for your database—offering control, accuracy, and peace of mind when it matters most.
Automated snapshots
Our system automatically takes full snapshots of the entire database server at scheduled intervals, securely retaining them for up to 120 days. These snapshots can capture either the complete server state—including multiple databases—or individual databases, offering flexible recovery options. In the event of a failure, outage, or data loss, they enable rapid, full restoration with minimal disruption. Automation ensures consistency, eliminates the risk of human error, and supports reliable audit trails, regulatory compliance, and long-term disaster recovery readiness.
Manual snapshots
Manual snapshots complement automated backups by giving administrators the ability to take on-demand backups before major updates, migrations, or configuration changes. These snapshots serve as restore points, allowing teams to quickly roll back if something goes wrong. Unlike automated snapshots, manual ones can be retained indefinitely or for custom periods, making them perfect for long-term archival, compliance purposes, or critical decision checkpoints. It adds a layer of operational flexibility and safety during planned interventions.
Backup health check: ensuring performance, compliance, and reliability
To ensure smooth and reliable backups for all critical servers beyond the primary database—such as application, caching, and file servers—AWS Backup is configured with automated scheduling and lifecycle policies. These policies manage when backups are taken, how long they’re retained, and when they’re deleted, reducing manual effort and providing consistency.
However, for added assurance of backup integrity, especially before major system changes or at key operational intervals, manual snapshot scripts are also executed. Running these scripts enables IT teams to confirm that the snapshot and backup process works flawlessly at the moment of execution, capturing the exact system state and highlighting any issues with permissions, dependencies, or configuration.
Proactive monitoring and alerting in blueBriX
blueBriX implements a comprehensive monitoring ecosystem for full visibility into performance, infrastructure health, and database optimization. Our dual-dashboard setup leverages AWS CloudWatch for real-time metrics and Nagios for custom and legacy monitoring—alongside continuous query analysis to ensure peak system performance and resolve issues proactively, before they affect patient care.
Real-time monitoring with cloudwatch dashboard
blueBriX leverages AWS CloudWatch dashboards to provide real-time, centralized visibility into server performance, resource utilization, and infrastructure health. These dashboards dynamically track key metrics—such as CPU, memory, inbound/outbound request counts, IOPS speed and so on—allowing IT teams to instantly identify performance bottlenecks, system overloads, or upcoming capacity issues. The real-time nature of CloudWatch means that any deviation from optimal functioning is detected the moment it occurs, empowering teams to act before minor anomalies develop into critical outages and triggering Email and Slack alerts to notify any anomaly in any of the servers.
In-depth server monitoring with Nagios dashboard
Nagios complements AWS CloudWatch by monitoring components CloudWatch doesn’t cover—like custom metrics, legacy systems, and non-AWS resources. It ensures full-stack visibility and instantly alerts the team (including via Email and Slack) if any critical service or process fails. This proactive monitoring helps catch issues outside the AWS environment, ensuring system reliability across the entire infrastructure.
Monitoring and addressing slow queries
Database health is continuously monitored for slow or inefficient queries that could degrade application performance. By reviewing query logs and analyzing execution times, we handover such queries to engineering team to optimize—ensuring smooth, responsive access to patient data and critical EHR functions.